《生成式AI用户风险感知与信息披露透明度报告》发布,腾讯混元评分最高
2024-12-25 12:02
AI
15款被测大模型产品无一披露训练数据来源;基于技术的局限性,各家均称无法完全保证AI生成内容的真实性和准确性;绝大多数大模型产品声明,会将用户输入的信息内容、提示语等用于模型训练,仅有4款允许用户撤回语音信息授权。
这是南都数字经济治理研究中心实测15款国产大模型的最新发现。
2024年12月18日下午,南都在京召开第八届啄木鸟数据治理论坛,会上重磅发布3.6万字的《生成式AI用户风险感知与信息披露透明度报告(2024)》(以下简称《报告》)。
《报告》呼吁增强大模型服务的透明度,它直接与模型是否可信挂钩,也关乎用户评估AI生成内容的准确性和可靠性,更好地识别潜在AI风险。
8款国产大模型信息透明度得分超过60分
缺乏透明度,是长期以来消费者使用数字技术面临的一个主要问题——比如在不知情的情况下,我们可能困于“信息茧房”里,陷于大数据“杀熟”的疑惑中,以及被诱导沉迷、过度消费等。
随着大模型的落地与普及,用户的“好奇”也在加深:它是如何设计的?用户的哪些数据会被用于AI训练?为何看似“聪明”的大模型会出现信息偏差,甚至算不准9.8和9.11哪个大?
要回答这些疑问,有赖于大模型信息透明度的提升。为了解当前国产大模型信息披露透明度情况,《报告》选取了15款大模型产品作为样本,通过隐私政策和用户协议测评,产品功能设计体验等方式,查看了各家批露的有关信息。
此次测评,主要从五个主要维度着手,包括个人信息保护、知识产权、内容安全、特殊群体保护、投诉反馈,并从五大测评类别细分出20个具体测评项;每项得分为5分,满分100。
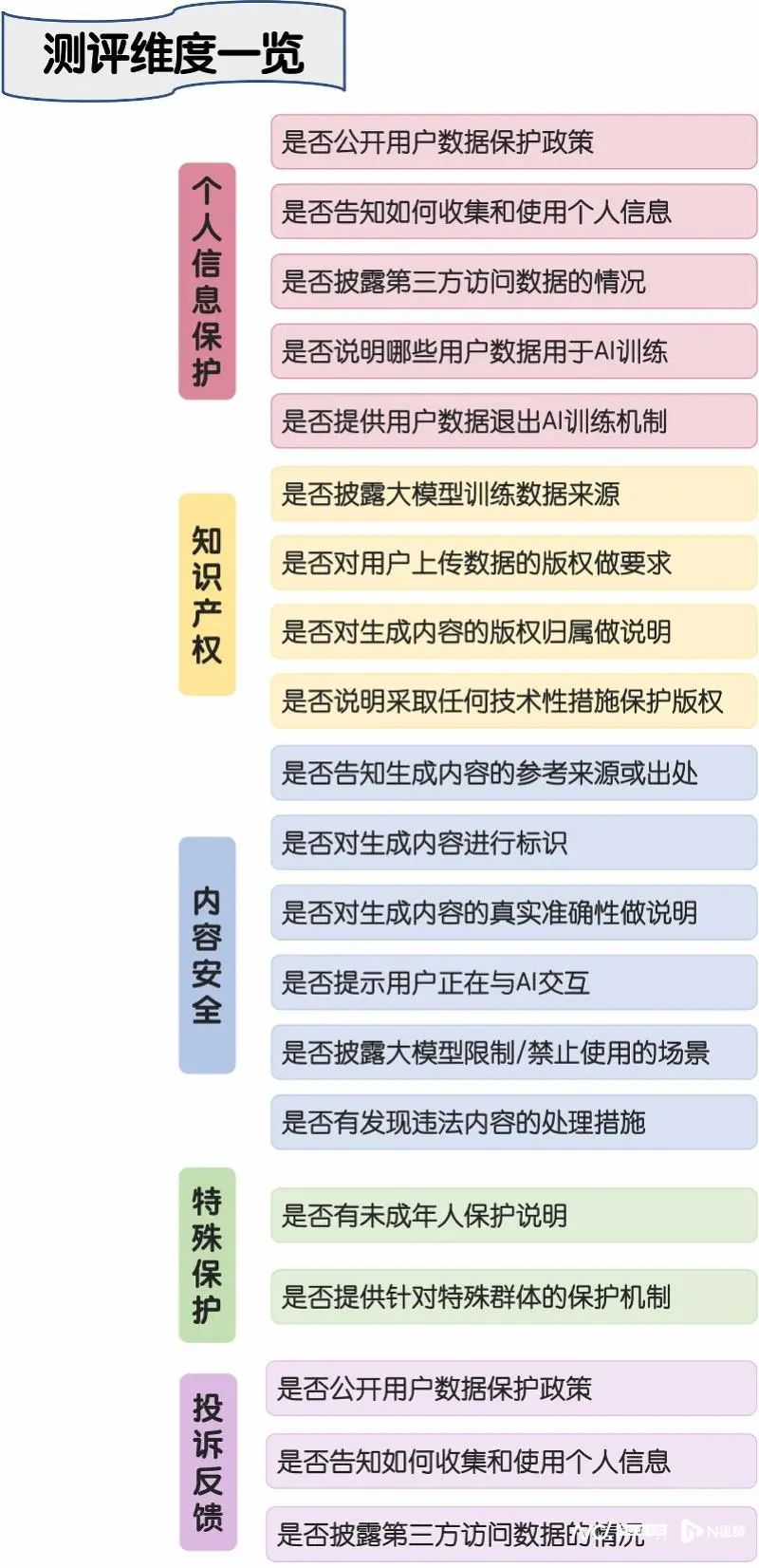
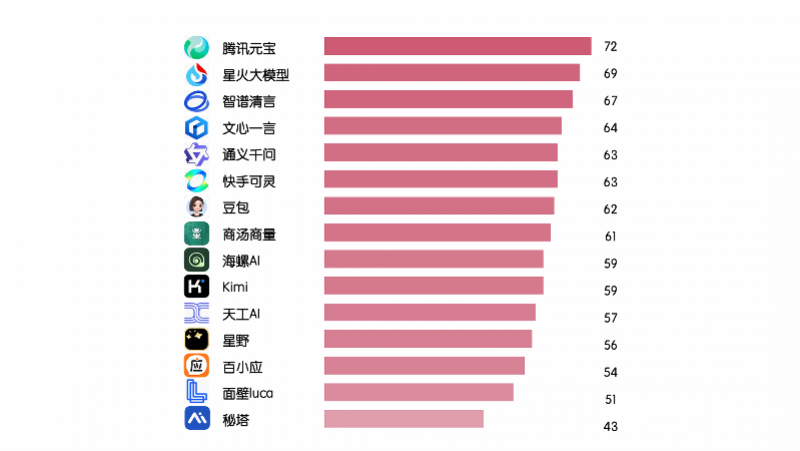
测评结果发现,15款AI大模型信息透明度的平均得分为60.2分。其中8款AI大模型信息透明度得分超过60分,它们大多出自头部互联网公司。
从排名情况看,得分最高前三位分别是腾讯元宝(72分)、星火大模型(69分)、智谱清言(67分);排名靠后的依次是百小应(54)、面壁Luca(51分)、秘塔(43分)。
从主要维度的得分情况看,15款AI大模型在个人信息保护方面做得相对透明。测评的样本中,在用户注册页面均能看到隐私政策,各家都会主动告知收集和处理用户个人信息,以及第三方数据访问情况,因此这三类得分均值基本接近100%。而普遍的失分点在于缺乏清晰的用户数据退出AI训练功能,此项得分均值仅有33%。
此次,被测AI大模型在内容安全方面也做得相对透明,全部都明确了大模型限制使用的场景,包括不得生成侵犯他人权益的内容等;且多数对生成内容进行标识,在AI交互页面也有“生成内容仅供参考”等提示。
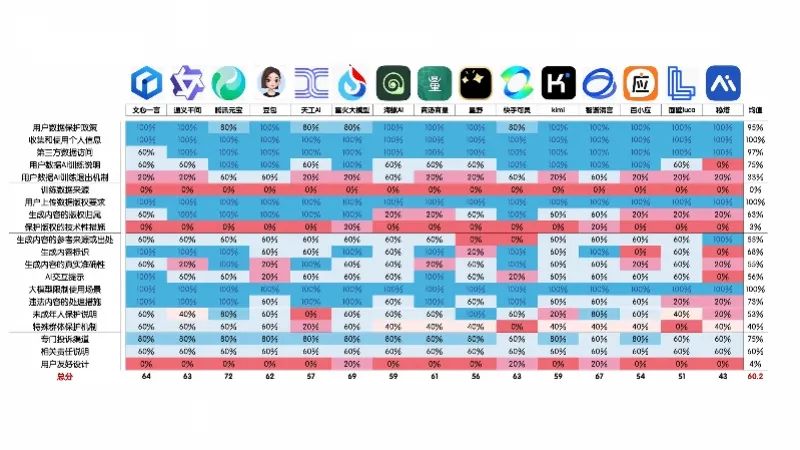
在知识产权方面,AI大模型信息透明度有待提升。测评发现,没有任何一家AI大模型主动告知训练模型所使用的数据集(包括版权数据)出自哪里,该项得分均为0。至于特殊群体保护、投诉反馈,各家的得分差异较小——特别是在用户友好设计加分项,基本未有亮眼表现。
仅有4款国产大模型允许用户撤回声音信息
具体而言,在个人信息保护方面,实测15款国产大模型均沿袭互联网应用的两大“标配”——用户协议和隐私政策。所有被测大模型均在隐私政策文本中设立专章详细说明用户如何收集和使用个人信息。
在与大模型交互过程中,用户数据通常会被用于模型的优化。如果未明确告知用户将使用哪些数据或者数据的使用范围过于模糊,可能导致用户担忧数据滥用的风险。而增强AI大模型透明度有助于用户做出知情选择,并理解其数据的使用方式。
对照ChatGPT、Claude、Gemini等全球顶尖大模型隐私政策可以看到,为保障用户的数据权益,企业多会主动声明如何以及将哪些用户数据投入AI训练,并做去标识化、匿名化处理,且提供一定退出机制。
此次实测中,绝大多数国产大模型均对此有所声明。比如,面壁Luca在用户协议声明,用户在使用本服务过程中使用的提示语、输入的信息内容,可能会被用于模型的进一步训练。天工AI也提及,会使用对话信息提高天工对用户输入内容的理解能力,以便不断改进天工的识别和响应的速度和质量。
那么,用户是否有权拒绝或撤回相关数据“投喂”AI训练?从实测来看,只有腾讯元宝、豆包、海螺AI、智谱清言等4家大模型提及允许用户拒绝授权,且多集中在语音信息的撤回授权。
比如豆包表示,如果用户不希望输入或提供的语音信息用于模型训练和优化,可以通过关闭“设置”-“账号设置”-“改进语音服务”来撤回授权;但如果用户不希望其他信息用于模型训练和优化,可以通过公示的联系方式与之联系,要求撤回将数据用于模型训练和优化。
值得一提的是,《报告》关注到,海外大模型做法在“用户数据退出AI训练机制”上,有不同做法。谷歌的Gemini提供了部分退出机制,用户可以关闭“Gemini 应用活动记录”来避免对话内容被用于AI训练,但是已经通过人工审核的数据将会独立保存。
ChatGPT Plus 用户可以通过设置禁用数据用于训练,这使他们的对话数据不会被用于进一步优化模型。然而,对于免费用户,数据通常会被默认收集并用于训练,用户无法完全选择退出,同时强调已被用于模型训练的数据无法撤销。
15款国产大模型无一披露训练数据来源
高质量的训练数据对大模型的重要性不言而喻,而训练数据集往往包含受版权保护的作品,如文本、图片、视频和音乐等。如果未经权利人的授权或满足合理使用的条件,这可能构成对版权的侵犯。
测评发现,15款国产大模型无一在政策协议中提及大模型训练数据的具体来源,更遑论公开披露使用了哪些版权数据。这一情况,在海外大模型的测评中也是如此,基本未主动提及训练模型的数据来源。
为什么大模型厂商不愿公开模型训练的数据来源?有观点认为,这可能是因为在数据来源不清晰的情况下,容易引起版权争端——在此类纠纷中,AI公司未经允许将受版权保护的内容用于训练AI模型,能否以合理使用作为抗辩理由,仍值得进一步探讨。
也有声音认为,这是出于竞争的考虑。如果强迫AI公司公开训练数据“秘方”,则有可能让竞争对手获悉并复制,而且一旦知道有专有数据集,各家都想抢占它,再通过排他性协议进行谈判,以此获得数据竞争的优势。还有观点指出,这也涉及数据安全的问题,担心公开的训练数据集被污染等。
这些回答反映了AI公司对完全披露模型训练来源的顾虑——当前或许不是公开的最好时机。但从长远来看,报告建议还是应尽可能多地发布有关基础模型的信息。因为公开模型训练数据集和提升算法透明度,可以让用户了解模型的训练基础、工作原理和决策逻辑,进一步评估模型的准确性和可靠性,并识别潜在的数据偏见和风险。
值得一提的是,2024年8月1日,欧盟《人工智能法》正式生效,其中也明确要求基础模型的供应商,声明是否使用受版权保护的材料来训练AI。这也反映了未来的监管方向。
尽管大模型厂商均未公开披露训练模型的数据集,但对用户上传数据的版权均会提出要求。各家的用户协议里,基本都有专条要求用户理解并承诺:在使用本产品过程中,上传的任何资料、素材等的知识产权均归您所有或已获得合法权利人授权,且不得侵犯他人包括知识产权在内的合法权益。
在AI生成内容的版权归属说明上,各家的情况则不同。只有智谱清言明确表示,“在适用法律允许的范围内,您基于智谱清言生成的内容的知识产权及其他权利由您享有。”
其他不少AI大模型则同时主张,如输入和/或输出本身包含了平台享有知识产权或其他合法权益的内容,则相应权利仍由公司享有。比如天工AI表示,“通过天工AI输出(生成)的音频形式内容(AI音乐内容),知识产权属于天工所有。”
技术受限,各家均称无法对AI生成内容完全保真
测评还发现,15款大模型产品均表示无法完全保证生成内容的真实性、准确性,主要原因是其服务所依赖的技术本身存在技术瓶颈,或受科技客观限制。
基于此,12款大模型产品在交互页面提示用户正在与AI对话,输出结果由机器生成。如百小应称“所有内容均由AI大模型输出,仅供参考,不代表我们的态度或观点”。文心一言和商汤大模型还在交互页面增强告知,布满“AI生成内容仅供参考”“内容由AI生成仅供参考”的水印。
为提高生成内容质量,各家在采取的措施方面存在明显差异。测评结果显示,有10款大模型产品在用户协议或隐私政策中承诺,将利用人工智能算法等技术对生成内容进行自动评估、过滤、审查等,从而增强内容真实性、准确性、客观性、多样性。腾讯元宝、天工AI、可灵三款还提到了机器与人工审查相结合,措施更加完备。
此外,15款大模型产品都设置专章,披露了用户在从事与其服务相关的所有行为时,限制、禁止使用的场景。测评发现,一个亮点是几乎所有被测大模型都提到了AI造假和生成有害信息的问题,规定不得利用其产品自行或者帮助他人上传、诱导生成、传播含有虚假、诈骗、有害、侵犯他人隐私等在道德上令人反感或违反法律法规的内容。
还有个别AI大模型对用户行为做了更为细致的限制。比如,海螺用户协议中有关被禁止行为的专章共有22小节,用户被禁止发布的内容还包括宣扬流量至上、奢靡享乐、炫富拜金等不良价值观;展现“饭圈”乱象和不良粉丝文化等。
星野作为一款主打AI陪伴的大模型产品,则规定禁止用户发表不友善对话,比如讽刺其他用户,阴阳怪气地表达批评;对其他用户创作的内容直接进行贬低性的评论等。
不仅如此,多数平台还按照相关管理办法规定,对图片、视频等生成内容进行标识。报告以生成一张AI图片进行实测,除不具备该功能的大模型外,9款生成的图片上都有相关标识。如腾讯元宝生成的图片右下角标明“腾讯元宝AI生成”,智谱清言则有“清言AI”标记。
同时多数平台还在政策协议中,明确禁止以任何方式删除、篡改、隐匿生成合成内容标识。
呼吁提升大模型透明度,增强用户信任
在特殊群里保护上,几乎所有被测大模型均在政策协议中提供就未成年人保护设置专章。但也有个别如天工AI提到“如果您是未成年人,为了保护您的合法利益,您应立即停止使用天工的产品或服务。
此次测评中,星野是唯一一家提供了未成年人保护模式的大模型产品。打开星野App伊始,页面弹出“青少年模式”提示框并设置实名认证功能。不过作为AI陪伴大模型,星野在政策协议也表示,该软件主要面向成人,原则上不向未成年人开放。
海螺AI则在平台自律公约上明确禁止不利于未成年人健康成长的内容,包括表现未成年人早恋的,以及抽烟酗酒、打架斗殴等不良行为;人物造型过分扩张怪异,对未成年人有不良影响的;利用未成年人制作不良节目等。
对于未成年人保护,国外AI陪伴类产品Character.AI有新的动作。在全球首例AI聊天机器人致死案发生后,Character.AI表示已为18岁以下用户增加了新的防护措施。这些防护措施包括减少“遇到敏感或暗示性内容的可能性”、改进干预措施、在“每次聊天时添加免责声明,提醒用户人工智能不是真人”,以及在用户使用平台一小时后发出通知。
在投诉反馈测评方面,大多数平台提供投诉反馈入口,大多承诺在15个工作日内反馈,用户可直接在网页版或App内提交意见。商量大模型承诺的反应速度最快,称收到投诉举报后将于10个工作日内提供反馈。
还有一家AI大模型就逝者账号权益作出规定。可灵AI表示,逝者近亲属可以通过其隐私政策载明的方式联系平台,在不违反逝者生前安排且不侵害他人和公众正当利益的前提下,完成身份核验手续后,查阅、复制、更正、删除逝者个人信息以行使法律法规规定的合法正当权益。
根据测评发现,《报告》也提出了相关建议。在个人信息保护方面,《报告》建议,赋予用户对个人数据的更多自主权,建议平台提供便捷的功能设计,让用户有权在设置中选择是否同意个人数据被用于模型训练。
此外,《报告》重申尊重知识产权和原创性。在充分考虑和平衡各方利益的情况下,探索出AI时代的版权保护路径,确保原创作品的保护与传播。
为了提高生成内容的质量,《报告》鼓励大模型平台采取机器与人工审查相结合的方式,增强内容真实性、准确性、客观性、多样性。同时建议加强对AI生成内容的标识要求,呼吁相关的管理办法和国标尽快出台,为产业界提供清晰指引和落地指南。
从整体来看,《报告》认为,AI厂商应重视大模型信息透明度问题,加强可解释性研究——比如可以提供相关的政策文件和规则,建立线上平台回应公众的关切等;以此更好地理解模型的决策过程和行为,增加用户信任度,并及时发现潜在的安全风险。
[免责声明:此文内容为广告,相关素材由广告主提供,广告主对本广告内容的真实性负责。本网发布目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责,请自行核实相关内容。广告内容仅供读者参考。]